Large Language Models are pretrained on large datasets that makes them very valuable to us for general knowledge, and whether its something like GPT or Bard, or if you are hosting your own LLM, making them more specialised and skillful in a certain domain can be accomplished by methods like fine tuning, or retraining, but these methods can be expensive and would need a good amount of processing time and iterating on the results of training or fine tuning can be also hard.
So the question became, what is a way to benefit from the power of LLMs, while giving it real time access to a specific subject or context that will be an addition to its knowledge and guarantee that the results are always precise and within the borders of the subject discussed with the user
Retrieval Augmented Generation (RAG) helped in introducing the concept of enriching LLMs with specific knowledge by utilizing the promopt context, which opened the possibility for focusing on improving and enhancing the context, and passing a piece of knowledge to the LLM, which allows the model to do what its best at with it, which is language tasks such as summarization, text generation, translation, classification, etc
Here's how it works on the surface:
[BEFORE] Straight to LLM Prompt
the LLM depending on its pretrained knowledge, will try to answer your question
[AFTER] Augmented Prompt
The retrieved information is used to augment the LLM's understanding of photosynthesis, providing up-to-date and precise details.
With LLMs being able to accept bigger context to work with, the RAG model is proven valuable in many use cases, as it allows the LLM to generate a response from a specific context, this makes the LLM more factual, and less likely to generate a response that is not related to the context.
Other Benefits of RAG Model
Brings more real time data to LLM to generate an answer from, instead of depending on the last time the LLM got trained
Fast testing and QA cycles, if the context is not of high quality, evaluations can be done quickly and the context can be enriched.
It is a cost effective solution.
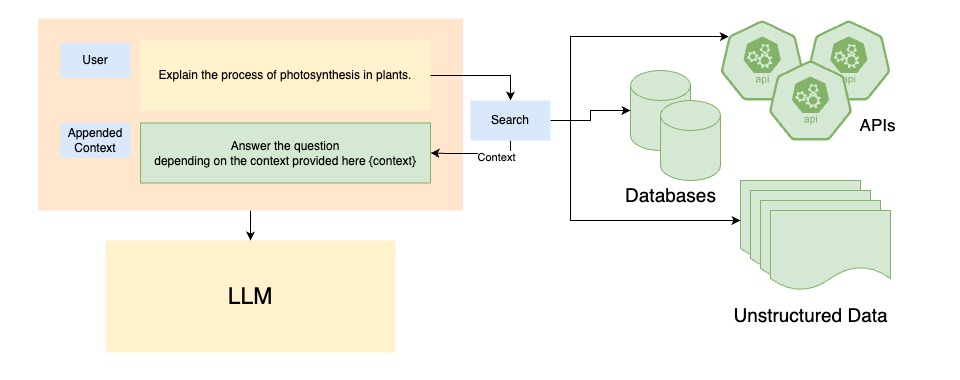
RAG Model Architecture
Since the model is allowing us to solve for context, the options are endless, whether it is data saved in raw text or structured in a database, or an API call that we need, once the data is fetched, the next step would be to embed it with the users prompt.
![[BEFORE] Straight to LLM Prompt](/img/prompt_before_rag.32b06485.jpg)
![[AFTER] Augmented Prompt](/img/prompt_after_rag.dd65d769.jpg)